 Les bases de données relationnelles
Les bases de données relationnelles
Bases de données: modélisation, manipulation et programmation
Afin de retrouver des informations très précises au sein d'une base de données, le langage SQL et certaines de ses clauses font appel, lors de leur résolution, à des opérations de synthèse ou de combinaison. Tel est le cas des clauses GROUP BY, des fonctions d'agrégation comme AVG ou COUNT ou des fonctions de jointure. Afin de maîtriser la rédaction de telles requêtes permettant d'obtenir les informations désirées, il peut s'avérer judicieux de regarder de plus près les mécanismes sur lesquels reposent ces opérations.
Le but des paragraphes suivants est de réaliser pas à pas une requête permettant de déterminer la liste triée des cantons romands dans lesquels le grossiste en livres possède plusieurs clients et d'en afficher pour chacun le nombre.
Commençons par créer une table de résultats contenant la liste des cantons romands dans lesquels le grossiste en livres possède des clients. Afin d'y voir plus clair, associons à chaque ligne de la table résultat, le nom du client associé ainsi que la ville dans laquelle il séjourne:

Liste des cantons romands dans lesquels séjournent des clients
Constatant que nous obtenons une liste dans laquelle un canton peut apparaître plusieurs fois, il pourrait s'avérer utile de regrouper les lignes par canton. La clause ORDER BY répond à ce besoin en nous permettant de trier le résultat final dans l'ordre croissant (ASC, ascendant) ou décroissant (DESC, descendant) des valeurs d'une ou de plusieurs colonnes.
La requête suivante retourne une liste de tous les clients romands en indiquant leurs noms, leurs villes et leurs cantons. La liste se présente dans l'ordre alphabétique croissant des cantons romands; à l'intérieur de chaque canton, les noms des clients apparaissent dans l'ordre alphabétique croissant:

Liste des clients ordonnée par canton
Nous constatons que nous avons effectivement plusieurs groupes de lignes dans la table de résultats obtenue et plus précisément un groupe de ligne(s) par canton romand:

Regroupement des clients par canton romand
Comme le montre l'exemple précédent, il est possible d'imbriquer plusieurs colonnes à trier. L'ordre de tri est déterminé par l'ordre de citation des noms de colonnes dans la clause ORDER BY. Ici, les cantons romands sont triés en premier, ensuite les noms des clients à l'intérieur de chaque canton.
A partir du résultat précédent, nous aimerions voir apparaître qu'une seule fois dans notre liste chaque canton et associer à chacun le nombre de clients y séjournant. A ce dessein, il est nécessaire de demander au SGBD de procéder à une seconde opération de traitement de notre table de résultat: une agrégation. De prime abord, les opérations de regroupement et d'agrégation sont très proches, pour ne pas dire pratiquement synonyme. En effet, étymologiquement, le mot "agrégation" signifie réunion d'éléments.
En matière de base de données, une opération d'agrégation est plus qu'un simple regroupement de lignes. L'opération d'agrégation génère une information ou plusieurs informations (apparaissant sous la forme d'une ligne dans la table de résultat) pour chaque groupe de lignes. Une agrégation transforme chaque groupe d'éléments en un élément unique de synthèse: l'agrégat. Illustrons ce propos à l'aide de la clause GROUP BY qui, contrairement à ce que son nom pourrait sous-entendre, n'induit pas qu'une simple opération de regroupement mais produit, à partir de ce regroupement d'éléments de même nature, une ou plusieurs nouvelle(s) information(s) à partir de chaque groupement de lignes réalisé.
La clause GROUP BY fait la synthèse des informations des lignes regroupées en extrayant la ou les informations se répétant. Prenons l'exemple avec les lignes regroupées sous l'égide des cantons romands: une fois chaque groupe constitué, l'opération d'agrégation de la clause GROUP BY va faire une synthèse des lignes appartenant au même groupe pour en sortir l'information essentielle qu'elles contiennent, à savoir le sigle du canton:

Agrégation des cantons romands
Afin d'obtenir une telle table de résultats, produit d'une opération de regroupement et d'une opération d'agrégation, il suffit de rédiger et de faire exécuter la requête SQL suivante:

Agrégation des cantons romands
Quoique le résultat obtenu semble être le même que celui retourné par la clause DISTINCT, il n'en est rien. En effet, la clause DISTINCT n'engendre pas un véritable processus d'agrégation lors de son traitement. Le SGBD se contente en effet de s'assurer qu'une même ligne n'apparaîtra pas plus d'une fois dans la table des résultats. Or une clause d'agrégation est capable de faire plus que cela, comme générer une nouvelle information à partir d'un groupe de lignes.
Imaginons par exemple que nous désirions récupérer pour chaque canton romand le nombre de clients y séjournant. Pour obtenir cette liste, il suffit de faire appel à une fonction d'agrégation telles que COUNT conjointement à la clause d'agrégation GROUP BY. GROUP BY partitionne d'abord la table Client en sous-ensembles (par groupes); ensuite, la fonction d'agrégation COUNT produit la somme des lignes au niveau de chaque groupe. Ainsi combinée avec la clause GROUP BY, la fonction d'agrégation retourne plusieurs valeurs, une pour chaque groupe:

Fonction d'agrégation comptant le nombre d'occurrences de lignes par canton romand
Une simple requête SQL permet d'effectuer ces deux opérations d'agrégation (agrégation de groupe et fonction d'agrégation). Cette requête permet ainsi de retourner le nombre de clients par canton romand enregistrés dans la table Client:

Dénombrement des clients par canton romand
Relevons que la clause DISTINCT ne permet pas d'obtenir une telle table de résultats précisément parce qu'elle ne repose pas sur un processus d'agrégation de données réunies en groupes, condition nécessaire pour qu'une fonction d'agrégation puisse faire son travail sur ces mêmes groupes.
Il est possible d'imbriquer les groupes. L'ordre de création des groupes est alors déterminé par l'ordre de citation des noms de groupes dans la clause GROUP BY. Ainsi, pour compter, par ville, le nombre de clients enregistrés dans la table Client et les présenter ces statistiques en groupant les villes par canton, il est nécessaire de recourir à la requête suivante:

Dénombrement des clients par canton romand
Nous constatons que Bulle et Fribourg, situées dans le canton de Fribourg occupent deux lignes adjacentes, de même que Genève et Nyon du canton de Genève.
Malgré l'apparente simplicité de la clause GROUP BY, elle risque de produire des résultats inattendus si nous ne prêtons pas attention à la logique de cette clause. En effet, quand GROUP BY est présente dans une instruction SQL, la déclaration des colonnes dans la clause SELECT doit obéir à la restriction suivante: seules les colonnes ayant une valeur unique par groupe sont admises.
Par exemple, dans la requête précédente, chaque groupe est formé d'une ville et d'un canton. La clause SELECT inclut deux colonnes, à savoir Canton et Ville. C'est logiquement correct car chaque combinaison d'une ville et d'un canton représente une valeur.
En revanche, dans la première requête de ce paragraphe, si la clause SELECT inclut aussi la colonne Ville, c'est logiquement faux car la clause ORDER BY partitionne la table Client en cantons. Etant donné que chaque canton possède plusieurs villes, la restriction énoncée ci-dessus (colonnes ayant une valeur unique par groupe) n'est plus respectée. En général, chaque colonne référencée dans la clause SELECT doit être incluse dans la clause GROUP BY, à moins qu'elle ne soit l'argument d'une fonction d'agrégat dans SELECT.
Il est fréquent que l'on souhaite voir dans la table des résultats que certaines lignes d'agrégation répondant à un ou plusieurs critères donnés. Imaginons par exemple que l'on ne souhaite obtenir dans notre table des résultats que les cantons romands dans lesquels le grossiste a plus d'un client. Nous serions tenté d'écrire la requête suivante à cet effet:

Requête SQL erronée
Cette requête n'est cependant pas acceptée par le SGBD qui retourne un message d'erreur. Cette erreur provient du fait que la clause WHERE permet de sélectionner (filtrer) des lignes individuellement et non les lignes résultant d'agrégation. Fort heureusement, une autre clause conditionnelle permet de dépasser cette limite: la clause HAVING. Cette dernière permet de sélectionner parmi les lignes agrégée générée par l'exécution de la clause GROUP BY celles répondant à une ou plusieurs conditions données. Au lieu d'identifier des lignes, HAVING identifie les groupes qui satisfont à un critère de sélection donné:

Liste des cantons ayant plusieurs clients
Les cantons avec un seul client n'apparaissent pas dans le résultat final. Deux cantons, Fribourg et Genève, satisfont au critère COUNT(Client)>1 avec 3 et 6 clients respectivement.
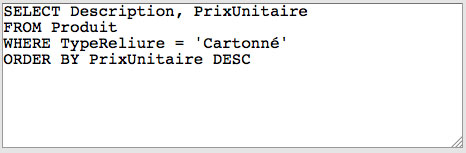
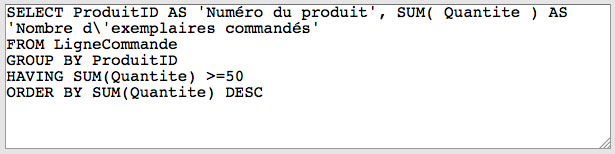
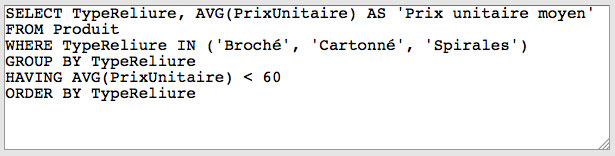
Rédigez les requêtes SQL suivantes permettant d'obtenir des informations à partir de la base de données Librairie. Vos solutions devront engendrer les mêmes tables que celles proposées dans le lien "Résultat" situé à la suite de l'énoncé de chaque requête:



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}